Ανάκτηση πληροφοριών από το Διαδίκτυο
Έχετε δοκιμάσει τα πάντα κι όμως ακόμα δεν έχετε στα χέρια σας τα δεδομένα που θέλετε. Τα δεδομένα που ναι μεν έχετε βρει στο Διαδίκτυο, όμως αλοίμονο –δεν υπάρχει τρόπος να τα κατεβάσετε, ενώ μέχρι και το copy-paste σας εγκατέλειψε. Μην ανησυχείτε, υπάρχει ακόμα τρόπος να τα αποκτήσετε. Για παράδειγμα θα μπορούσατε:
-
Να πάρετε τα δεδομένα αυτά από διαδικτυακές διεπαφές (ή API) που παρέχονται από διαδικτυακές βάσεις δεδομένων και πολλές σύγχρονες εφαρμογές (όπως το Twitter, το Facebook και πολλές άλλες). Με αυτόν τον τρόπο μπορείτε να έχετε εύκολη πρόσβαση σε δεδομένα κυβερνητικού ή εμπορικού περιεχομένου, καθώς και σε δεδομένα από μέσα κοινωνικής δικτύωσης.
-
Να εξάγετε πληροφορίες από αρχεία PDF. Πρόκειται για δύσκολο εγχείρημα, καθώς το PDF αποτελεί γλώσσα εκτυπωτών και δε συγκρατεί πολλές πληροφορίες σχετικά με τη δομή των δεδομένων, οι οποίες εμπεριέχονται σε ένα έγγραφο. Αν και η ανάκτηση στοιχείων από αρχείο PDF δεν εξετάζεται σε αυτό το βιβλίο, υπάρχουν διάφορα εργαλεία και βοηθητικά βίντεο.
-
• Ιστοσελίδες για screen scrape. Κατά τη διαδικασία του screen scrape, ανακτάτε πληροφορίες σχετικά με τη δομή του περιεχομένου μιας κανονικής ιστοσελίδας με τη βοήθεια μιας εφαρμογής scraping ή με τη δημιουργία κάποιου μικρού κώδικα. Η μέθοδος αυτή μπορεί να αποτελέσει ένα σημαντικό εργαλείο με πολλαπλές δυνατότητες, αλλά απαιτεί κάποιες γνώσεις σχετικά με το διαδίκτυο.
Μην παραμελείτε όμως με όλες αυτές τις τεχνικές επιλογές κάποιες απλούστερες διαδικασίες: συχνά αρκεί να ψάξετε για ένα αρχείο με δεδομένα αναγνώσιμα από μηχανή ή να επικοινωνήσετε με το φορέα που διαθέτει τις πληροφορίες που θέλετε.
Αυτό το κεφάλαιο αποτελεί ένα πολύ βασικό παράδειγμα ανάκτησης πληροφοριών από ιστοσελίδα σε μορφή HTML.
Τι είναι τα Δεδομένα Αναγνώσιμα από Μηχανή;
Όλες αυτές οι μέθοδοι αποσκοπούν στην πρόσβαση σε δεδομένα αναγνώσιμα από μηχανή. Τα δεδομένα αυτά προορίζονται για επεξεργασία από υπολογιστή, αντί για την άμεση παρουσίασή τους στον (άνθρωπο) χρήστη. Η δομή τους σχετίζεται με τις πληροφορίες που περιέχουν και όχι με την τελική οπτική μορφή τους. Μερικά παραδείγματα τέτοιων δεδομένων αποτελούν τα CSV, XML, JSON, και τα αρχεία Excel, ενω έγγραφα του Word, σελίδες ΗΤΜL και αρχεία PDF αφορούν περισσότερο την οπτική μορφή των πληροφοριών. Για παράδειγμα, ένα αρχείο PDF αποτελεί μια μορφή γλώσσας που απευθύνεται κατευθείαν στον εκτυπωτή σας και έχει να κάνει περισσότερο με τη θέση των γραμμών και των τελείων σε μια σελίδα παρά με τους διακριτέους χαρακτήρες της.
Scraping Websites: Για ποιο λόγο;
O καθένας το χει επιχειρήσει: είστε σε μια ιστοσελίδα, βλέπετε έναν ενδιαφέροντα πίνακα και προσπαθείτε να τον αντιγράψετε στο Excel για να προσθέσετε αργότερα κάποια νούμερα ή να τον αποθηκεύσετε για μελλοντική χρήση. Ωστόσο, αυτό δε συμβαίνει πάντα ή μπορεί οι πληροφορίες που ζητάτε να βρίσκονται διασκορπισμένες σε πολλές διαφορετικές σελίδες. Καθώς η αντιγραφή με το χέρι είναι κουραστική, είναι πιο λογικό να χρησιμοποιήσετε έναν κώδικα.
Το πλεονέκτημα του scraping είναι ότι εφαρμόζεται σε κάθε ιστοσελίδα, από την πρόγνωση του καιρού μέχρι τις κρατικές δαπάνες, ακόμα κι αν η σελίδα δε διαθέτει διεπαφή για πρόσβαση σε ανεπεξέργαστα δεδομένα.
Scrape: Τι μπορείτε και τι δεν μπορείτε να κάνετε
Υπάρχουν φυσικά και περιορισμοί στο scraping. Μερικοί από τους παράγοντες που δυσκολεύουν τη διαδικασία αυτή είναι οι εξής:
-
Κακοφορμισμένος κώδικας HTML με καθόλου ή ελάχιστες πληροφορίες σχετικά με τη δομή (όπως σε παλαιότερες κυβερνητικές ιστοσελίδες).
-
Συστήματα πιστοποίησης που προορίζονται για να εμποδίζουν την αυτόματη πρόσβαση (όπως οι κώδικες CAPTCHA και τα paywalls).
-
Συστήματα session-based που χρησιμοποιούν cookies από το πρόγραμμα περιήγησης για να καταγράφουν τις δραστηριότητες του χρήστη.
-
Έλλειψη μιας ολοκληρωμένης καταχώρησης των αντικειμένων και πιθανές αναζητήσεις με μπαλαντέρ χαρακτήρες.
-
Απαγόρεψη πρόσβασης στα δεδομένα από τους διαχειριστές των εξυπηρετητών
Ένα πρόσθετο είδος περιορισμών αποτελούν τα νομικά εμπόδια: κάποιες χώρες αναγνωρίζουν τα δικαιώματα στις βάσεις δεδομένων. Ως εκ τούτου, έχετε περιορισμένο δικαίωμα αναπαραγωγής ήδη δημοσιευμένων πληροφοριών στο διαδίκτυο. Μπορείτε βέβαια να αγνοήσετε αυτήν την παράμετρο και να ενεργήσετε πάραυτα. Αυτό όμως εξαρτάται από τη δικαιοδοσία σας –μπορεί να έχετε ειδικά δικαιώματα ως δημοσιογράφος. Το scraping σε διαθέσιμα κυβερνητικά δεδομένα επιτρέπεται, καλό θα ήταν όμως να είστε σίγουρος, πριν τα δημοσιεύσετε. Εμπορικοί οργανισμοί –και κάποιες ΜΚΟ- είναι λιγότερο ανεκτικοί και μπορεί να ισχυριστούν ότι «σαμποτάρετε» την πολιτική τους. Άλλες πληροφορίες παραβιάζουν την ιδιωτικότητα του πολίτη και καταστρατηγούν νόμους σχετικά με το απόρρητο δεδομένων ή την επαγγελματική ηθική.
Εργαλεία που βοηθούν το Scrape
Τα προγράμματα για την ανάκτηση τεράστιου όγκου πληροφοριών από ιστοσελίδες αφθονούν, ενώ περιλαμβάνουν πρόσθετα φυλλομετρητή και κάποιες διαδικτυακές υπηρεσίες. Ανάλογα με το φυλλομετρητή σας, εργαλεία όπως το Readability (για την ανάκτηση του κειμένου από μια σελίδα) ή το DownThemAll (για να κατεβάζετε πολλά αρχεία ταυτόχρονα) αυτοματοποιούν κουραστικές διαδικασίες, ενώ το πρόσθετο Scraper του Chrome δημιουργήθηκε ακριβώς για την ανάκτηση πίνακα από ιστοσελίδες. Τα πρόσθετα του κατασκευαστικού λογισμικού όπως το FireBug (για τον Firefox, ενώ υπάρχει ήδη το αντίστοιχο πρόγραμμα για τα Chrome, Safari και ΙΕ) σας επιτρέπουν να καταγράψετε πώς ακριβώς είναι η δομή μιας ιστοσελίδας και τι μηνύματα ανταλλάσσονται μεταξύ του προγράμματος περιήγησής σας και του εξυπηρετητή.
Το ScraperWiki είναι μια ιστοσελίδα που σας παρέχει τη δυνατότητα να κωδικοποιήσετε scrapers σε πολλές διαφορετικές γλώσσες προγραμματισμού, όπως οι Python, Ruby και PHP. Αν θέλετε να αποφύγετε το δύσκολο εγχείρημα της δημιουργίας περιβάλλοντος προγραμματισμού στον υπολογιστή σας και θέλετε να ξεκινήσετε κατευθείαν το scraping, τότε αυτός είναι ο τρόπος. Άλλες διαδικτυακές υπηρεσίες, όπως το Google Spreadsheets και το Yahoo! Pipes σας επιτρέπουν επίσης να ανακτήσετε κάποιες πληροφορίες από ιστοσελίδες.
Πώς λειτουργεί ένας Web Scraper;
Οι Web Scrapers είναι συνήθως μικρά κομμάτια κώδικα γραμμένα σε μια γλώσσα προγραμματισμού όπως οι Python, Ruby ή PHP. Η επιλογή της γλώσσας εξαρτάται σε μεγάλο βαθμό από την κοινότητα στην οποία έχετε πρόσβαση: εάν κάποιος στο γραφείο τύπου ή στην πόλη σας δουλεύει ήδη με μια από αυτές τις γλώσσες, καλό θα ήταν να χρησιμοποιήσετε την ίδια.
Παρόλο που μπορεί κάποια εύκολα προαναφερθέντα εργαλεία να είναι χρήσιμα στην αρχή, η πραγματική δυσκολία του scraping βρίσκεται στον εντοπισμό των σωστών σελίδων και των σωστών στοιχείων μέσα σε αυτές, προκειμένου να ανακτήσετε τις πληροφορίες που επιθυμείτε. Οι διαδικασίες αυτές δε σχετίζονται με τον προγραμματισμό, αλλά με την κατανόηση της δομής της ιστοσελίδας και της βάσης δεδομένων.
Κατά την προβολή μιας ιστοσελίδας, το πρόγραμμα περιήγησής σας θα χρησιμοποιήσει δύο τεχνολογίες: την HTTP, για να επικοινωνήσει με τον εξυπηρετητή και να ζητήσει συγκεκριμένες πληροφορίες όπως έγγραφα, εικόνες ή βίντεο, και το HTML, τη γλώσσα κατασκευής ιστοσελίδων.
Η Ανατομία μιας Ιστοσελίδας
Κάθε ιστοσελίδα είναι δομημένη σαν μια ιεραρχία κουτιών (που ορίζονται από τις «ετικέτες» του HTML). Ένα μεγάλο κουτί περιέχει πολλά μικρότερα –για παράδειγμα, ένας πίνακας αποτελείται από μικρότερα τμήματα: τις σειρές και τα κελιά. Υπάρχουν πολλά είδη ετικέτας για διαφορετικές λειτουργίες –κάποια δημιουργούν κελιά κι άλλα πίνακες, εικόνες ή συνδέσμους. Μπορούν επίσης να έχουν πρόσθετες δυνατότητες (κάποια είναι μοναδικά αναγνωριστικά), να ανήκουν σε ομάδες, τις επωνομαζόμενες «τάξεις» που επιτρέπουν τον εντοπισμό και την καταγραφή μεμονωμένων στοιχείων σε ένα έγγραφο. Η επιλογή των κατάλληλων στοιχείων με αυτόν τον τρόπο και η ανάκτηση του περιεχομένου τους αποτελούν σημαντικά βήματα για το γράψιμο ενός scraper.
Κατά την προβολή των στοιχείων μιας ιστοσελίδας είναι δυνατός ο διαχωρισμός τους σε κουτιά μέσα σε άλλα κουτιά.
Για το scrape σε ιστοσελίδες, πρέπει να γνωρίζετε κάποια πράγματα σχετικά με τα διαφορετικά είδη στοιχείων που βρίσκονται σε ένα έγγραφο HTML. Για παράδειγμα, το στοιχείο <table> περιλαμβάνει έναν πίνακα, ο οποίος έχει <tr> στοιχεία (σειρές πίνακα) για τις σειρές του που με τη σειρά τους περιλαμβάνουν <td> (δεδομένα πίνακα) για κάθε κελί. Το πιο κοινό στοιχείο που θα συναντήσετε είναι το <div> που ουσιαστικά περιλαμβάνει κάθε στοιχείο περιεχομένου. Ο ευκολότερος τρόπος για να καταλάβετε τη σημασία των στοιχείων αυτών είναι με το πρόγραμμα developer toolbar στο πρόγραμμα περιήγησής σας: έτσι θα μπορέσετε να δείτε οποιαδήποτε ιστοσελίδα μαζί με τον υποκείμενο κώδικά της.
Oι ετικέτες μοιάζουν με βιβλιοστάτες, καθώς σηματοδοτούν την αρχή και το τέλος μιας ενότητας. Για παράδειγμα, η ετικέτα <em> συμβολίζει την αρχή μιας φράσης με πλάγιους χαρακτήρες ενώ το </em> συμβολίζει το τέλος της. Εύκολο.
Παράδεγιμα: Κάνωντας scrap Πυρηνικά ατυχήματα με την Python
Το NEWS είναι η πύλη του Διεθνούς Οργανισμού Πυρηνικής Ενέργειας (IAEA) για τα ατυχήματα ακτινοβολίας σε παγκόσμια κλίμακα (και πιθανή υποψήφια για ένταξη στην ομάδα Περίεργων Ονομάτων!). Η ιστοσελίδα περιλαμβάνει λίστες των ατυχημάτων με απλό τρόπο -σαν blog- που ευνοεί το scraping.
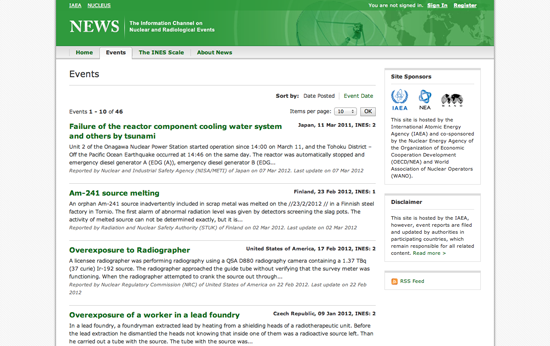
Αρχικά, δημιουργήστε έναν καινούριο Python Scraper στο ScraperWiki. Θα εμφανιστεί ένα έγγραφο που θα περιέχει μόνο το σκελετό ενός κώδικα. Σε άλλο παράθυρο, ανοίξτε την ιστοσελίδα του IAEA και το developer toolbar του προγράμματος περιήγησής σας. Στην προβολή «Στοιχείων», επιχειρήστε να εντοπίσετε το στοιχείο HTML για ένα από τα αντικείμενα τίτλων. Το developer toolbar σας βοηθά να συνδέσετε τα στοιχεία της ιστοσελίδας με τον υποκείμενο κώδικα HTML.
Με την επεξεργασία της ιστοσελίδας θα ανακαλύψετε ότι οι τίτλοι αποτελούν στοιχεία <h4> ενός <table>. Κάθε γεγονός αποτελεί μια <tr> σειρά, η οποία περιλαμβάνει μια περιγραφή και ημερομηνία. Αν επιθυμείτε να εξάγετε τους τίτλους όλων των γεγονότων, θα πρέπει να επιλέξετε κάθε σειρά του πίνακα διαδοχικά και να πάρετε το κείμενο που περιλαμβάνεται στα στοιχεία των τίτλων.
Προκειμένου να μετατρέψουμε αυτή τη διαδικασία σε κώδικα, χρειάζεται να κατανοήσουμε όλα τα βήματα. Για να κατανοήσετε τι βήματα απαιτούνται, ας παίξουμε ένα απλό παιχνίδι: στο παράθυρο του ScraperWiki, προσπαθήστε να γράψετε οδηγίες για τον εαυτό σας σχετικά με κάθε σας βήμα σε αυτή τη διαδικασία, σαν την εκτέλεση μιας συνταγής (ξεκινήστε κάθε γραμμή με μια δίεση, ώστε να ξέρει ο Python ότι δεν πρόκειται για πραγματικό κώδικα). Για παράδειγμα:
# Εντόπισε κάθε σειρά του πίνακα # Tο Unicorn δεν πρέπει να εξέχει αριστερά.
Προσπαθήστε να είστε όσο το δυνατόν πιο ακριβής, υποθέτοντας ότι το πρόγραμμα δε γνωρίζει τίποτα για τη σελίδα που θέλετε να κάνετε scrape.
Συγκρίνετε αυτόν τον ψευδοκώδικα με τον πραγματικό κώδικα για το πρώτο σας scraper:
import scraperwiki from lxml import html
Αρχικά, εισάγουμε υπάρχουσες λειτουργίες από βιβλιοθήκες –μικρά κομμάτια έτοιμου κώδικα. Το scraperwiki μας επιτρέπει να κατεβάσουμε ιστοσελίδες, ενώ με το lxml μπορούμε να αναλύσουμε τη δομή των εγγράφων HTML. Τα καλά νέα είναι ότι αν γράφετε scraper σε γλώσσα Python με το ScraperWiki, αυτές οι δύο γραμμές είναι πάντα ίδιες.
url = "http://www-news.iaea.org/EventList.aspx" doc_text = scraperwiki.scrape(url) doc = html.fromstring(doc_text)
Στη συνέχεια, ο κώδικας παράγει ένα όνομα (μεταβλητή): το url και αποδίδει το URL της σελίδας IAEA ως τιμή. Έτσι πληροφορείται ο scraper για την ύπαρξη και τη σημασία της σελίδας. Προσέξτε ότι το URL βρίσκεται σε εισαγωγικά καθώς δεν αποτελεί μέρος του κώδικα, αλλά μια σειρά, μια διαδοχή χαρακτήρων.
Στη συνέχεια, εισάγουμε τη μεταβλητή του url σε ένα λειτουργικό σύστημα, το scraperwiki.scrape. Το σύστημα αυτό εκτελεί μια συγκεκριμένη λειτουργία –στην περίπτωση αυτή, θα κατεβάσει μια ιστοσελίδα. Όταν ολοκληρώσει την ενέργεια αυτή, θα αναθέσει το αποτέλεσμα σε μια άλλη μεταβλητή, doc_text, το οποίο θα εμπεριέχει το κείμενο της ιστοσελίδας. Δεν πρόκειται για την οπτική μορφή του κειμένου που εμφανίζεται στον περιηγητή σας, αλλά για την πηγή του κώδικα μαζί με τις ετικέτες. Καθώς η μορφή αυτή παρουσιάζει δυσκολίες στην ανάλυσή της, θα χρησιμοποιήσουμε μια άλλη λειτουργία, το html.fromstring, για να δημιουργήσουμε μια ειδική αναπαράσταση, το μοντέλο αντικειμένων εγγράφων (DOM), ώστε να εντοπίσουμε εύκολα τα διάφορα στοιχεία.
for row in doc.cssselect("#tblEvents tr"):
link_in_header = row.cssselect("h4 a").pop()
event_title = link_in_header.text
print event_title
Σε αυτό το τελικό στάδιο, χρησιμοποιούμε το DOM για να βρούμε κάθε σειρά στον πίνακά μας και να πάρουμε τον τίτλο του γεγονότος από την επικεφαλίδα. Επιπλέον, χρησιμοποιούμε δύο νέες λειτουργίες: μία for-loop και μία για επιλογή στοιχείων (.cssselect). Η εντολή for-loop κάνει αυτό που λέει και το όνομά της: θα διαβάσει μια λίστα αντικειμένων, δίνοντας στο καθένα ένα προσωρινό ψευδώνυμο (row στην περίπτωσή μας) και μετά θα τρέξει ό,τι οδηγίες αντιστοιχούν στο καθένα.
Η άλλη νέα λειτουργία, η επιλογή στοιχείων, χρησιμοποιεί μια ειδική γλώσσα, προκειμένου να εντοπίσει στοιχεία στο έγγραφο. Οι επιλογείς CSS αξιοποιούνται συνήθως για την προσθήκη πληροφοριών διάταξης σε στοιχεία HTML και για την ακριβή επιλογή των στοιχείων από μια σελίδα. Σε αυτήν την περίπτωση (γραμμή 6), επιλέγουμε #tblEvents tr, το οποίο αντιστοιχεί στη συνέχεια κάθε <tr> του πίνακα με την ταυτότητα tblEvents (η δίεση συμβολίζει την ταυτότητα). Αυτή η λειτουργία θα μας δώσει μια λίστα στοιχείων <tr>.
Το αποτέλεσμα αυτό είναι εμφανές στην επόμενη γραμμή (7), όπου χρησιμοποιούμε έναν άλλο επιλογέα για να βρούμε το <a> (έναν υπερσύνδεσμο) μέσα στο <h4> (έναν τίτλο). Εδώ θέλουμε απλώς να εντοπίσουμε ένα μεμονωμένο στοιχείο (καθώς υπάρχει μόνο ένας τίτλος ανά σειρά) το οποίο πρέπει να αφαιρέσουμε από την κορυφή της λίστας του επιλογέα μας με τη λειτουργία .pop().
Μερικά στοιχεία του DOM περιέχουν πραγματικό κείμενο (δηλ. κείμενο που δεν ανήκει σε γλώσσα σήμανσης) το οποίο μπορούμε να επεξεργαστούμε με την εντολή [element].text στη γραμμή 8. Στο τέλος, στη γραμμή 9, τυπώνουμε το κείμενο αυτό στην κονσόλα του ScraperWiki. Αν δώσετε την εντολή run στο scraper σας, θα πρέπει στο μικρότερο παράθυρο να ξεκινήσει η καταγραφή των ονομάτων των γεγονότων που βρίσκονται στη σελίδα του ΙΑΕΑ.
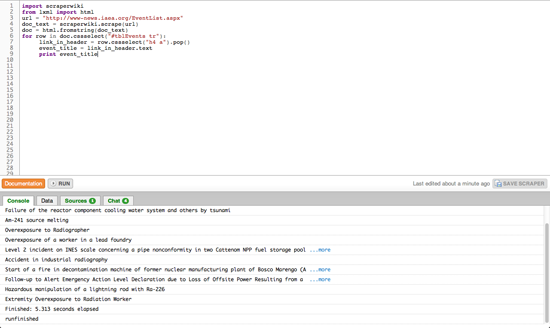
Πλέον μπορείτε να δείτε πώς λειτουργεί ένας βασικός scraper: κατεβάζει την ιστοσελίδα, τη μεταγράφει σε μορφή DOM και μετά σας επιτρέπει να διαλέξετε και να ανακτήσετε συγκεκριμένο περιεχόμενο. Με βάση αυτό το σκελετό, μπορείτε να λύσετε κάποια από τα υπόλοιπα προβλήματα με τη βοήθεια του ScraperWiki και της γλώσσας Python:
-
Μπορείτε να βρείτε τη διεύθυνση του συνδέσμου σε κάθε τίτλο γεγονότος;
-
Μπορείτε να επιλέξετε το κουτάκι με την ημερομηνία και το μέρος με τη βοήθεια του CSS class name του και να ανακτήσετε το κείμενο του στοιχείου;
-
Το ScraperWiki περιέχει μια μικρή βάση δεδομένων για κάθε scraper, όπου μπορείτε να αποθηκεύετε αποτελέσματα. Αντιγράψτε το αντίστοιχο παράδειγμα από τα έγγραφά τους και τροποποιήστε το, ώστε να αποθηκεύει τους τίτλους των γεγονότων, τους συνδέσμους και τις ημερομηνίες.
-
Η λίστα με τα γεγονότα αποτελείται από πολλές σελίδες. Μπορείτε να κάνετε scrape σε όλες αυτές και να ανακτήσετε και ιστορικά γεγονότα;
Καθώς προσπαθείτε να λύσετε αυτά τα προβλήματα, μπορείτε να εξερευνήσετε παραπάνω τις δυνατότητες του ScraperWiki: υπάρχουν πολλά χρήσιμα παραδείγματα στους scrapers με δεδομένα που μπορούν ακόμα και να σας εντυπωσιάσουν. Με αυτόν τον τρόπο, δε χρειάζεται να ξεκινάτε τον scraper σας από το μηδέν: διαλέξτε απλώς κάποιον παρόμοιο, δώστε την εντολή fork και προσαρμόστε τον στις ανάγκες του προβλήματός σας.
— Friedrich Lindenberg, Open Knowledge Foundation